Linux Shell 脚本分割CSV文件
将以下脚本保存为 split_csv.sh
然后执行 split_csv.sh data.csv 100
可以将 data.csv 按照每个文件 100 行数据,分割为多个小文件,命名格式为:
data_0000.csv data_0001.csv data_0002.csv data_0003.csv data_0004.csv ...
脚本:
1 |
|
将以下脚本保存为 split_csv.sh
然后执行 split_csv.sh data.csv 100
可以将 data.csv 按照每个文件 100 行数据,分割为多个小文件,命名格式为:
data_0000.csv data_0001.csv data_0002.csv data_0003.csv data_0004.csv ...
脚本:
1 |
|
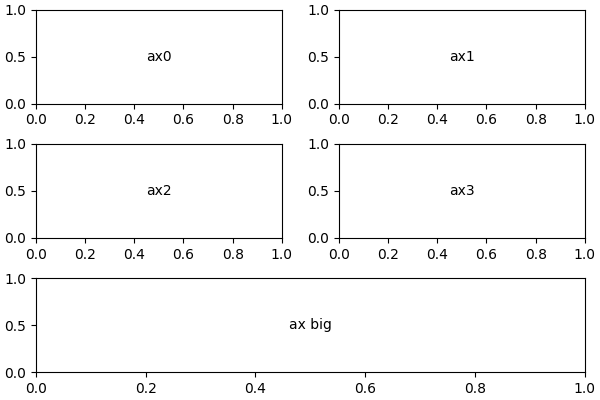
matplotlib 中 subplots 时,合并多个子图, 实现类似 Excel中 “合并单元格”的功能。
例如:创建一个 3 行 2 列的 figure,将最后一行合并
1 | import matplotlib.pyplot as plt |
效果:
Python 将词典扁平化,
例如:
1 | # 原始数据 |
主要思路是迭代,这里给出两种实现方法。
1 | def flatten(d): |
1 | def flatten(d, prefix=None): |
联网环境下,可使用阿里云镜像,方法参照:
https://liangxinhui.tech/2019/07/18/docker-install-aliyun/
离线安装,可用二进制包,直接解压即可使用。
Dockerfile 作为构建 Docker 镜像的描述文件。
持续更新..
整理记录常用 shell 代码段。
1 | # 获取当前脚本所在目录 |
1 | # 判断文件夹是否存在 |
1 | # for 循环 (需要bash执行,ubuntu 默认sh不支持此语法) |
1 | # 取第N个参数,如果不存在,设置默认值 |
1 | # 判断命令是否存在 |